Personalized route recommendation

With +100k climbing routes worldwide, how do I choose the next destination? Over the years, I rated climbs on Mountain Project and I want to use these to recommend my next routes to climb.
I built a supervised neural network that learns my climbing taste from route description. For every route I haven’t climbed yet, the model estimates the probability that it resembles my previous highly rated climbs and ranks them. The model also recommends climbing areas that best align with my personal climbing style. The codes can be found on here on GitHub. If you want to try it yourself, all you need to do is download your ticks from Mountain Project. In the next blog I will share a route recommender version which takes climbing features as input, which is useful if you want to try different styles, or if you haven’t tracked enough routes to make reliable predictions.
Personal likes
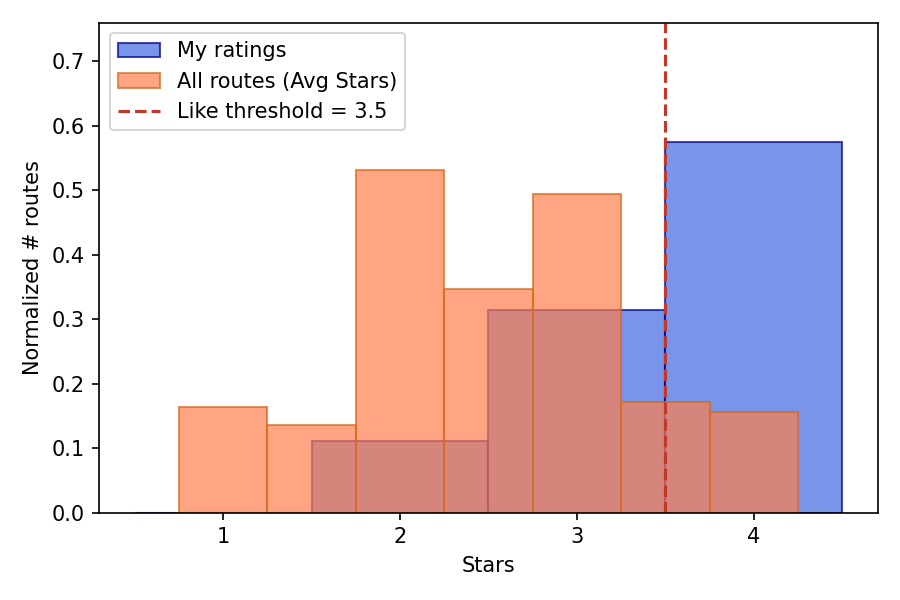
Routes on Mountain Project are rated between 0-4. I have 72 personal ticks of which 55 are used for learning as they have sufficient description. I appear to rate generously and mostly track the routes I’ve liked, as shown in the histogram below where I compare my likes and the average likes from the +100k routes. To translate the ratings into binary like/not-like, I set a threshold at 3.5 for the community averaged votes, while for my own votes I use a personalized threshold as described below, since my ratings are biased towards higher values.
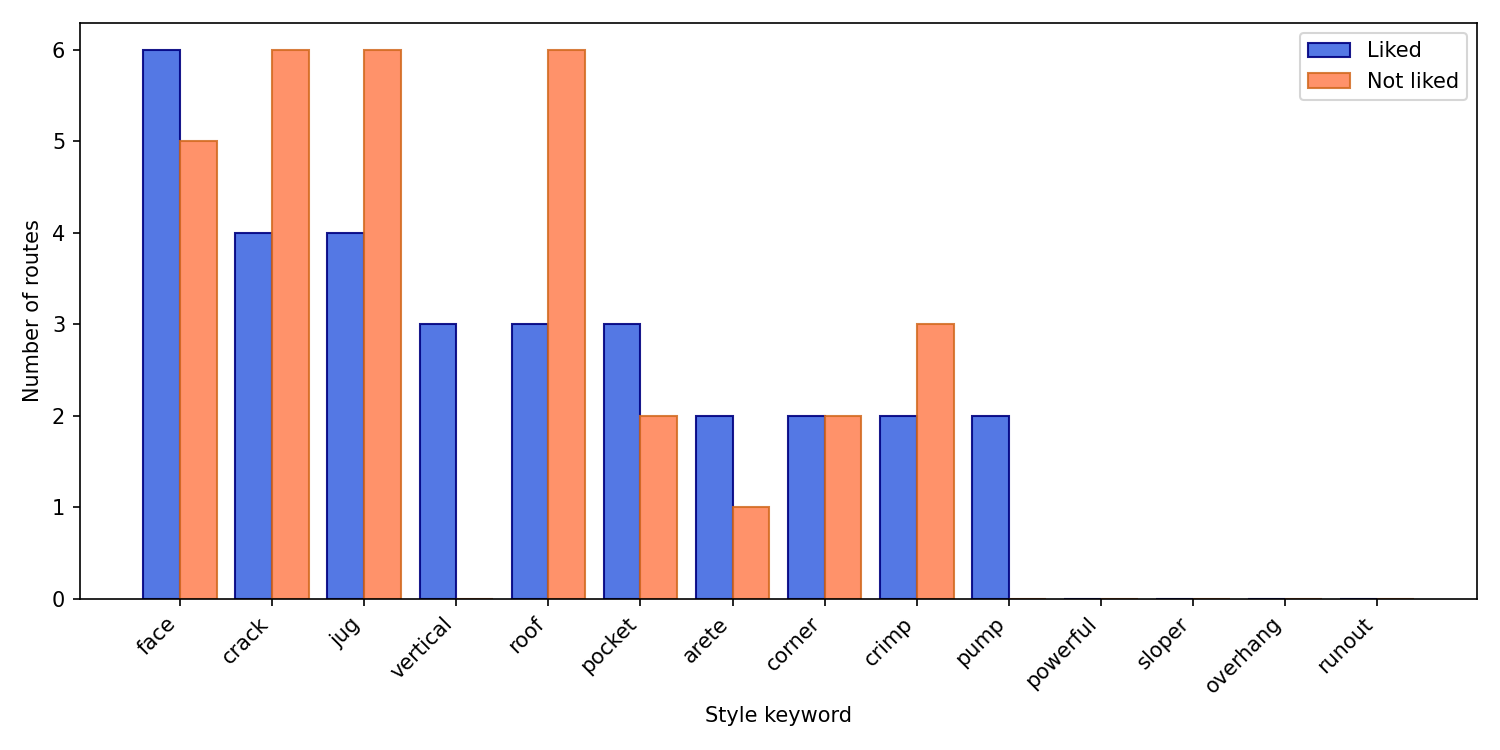
Based on the keywords describing climbing features I found in Blog 1, I show below the top keywords from my ticked routes with a mild preference for vertical face climbing (yes my favorites!), and less interest in powerful overhang climbs that have cracks or jugs. Let’s now train the model to learn what high-rated climbing routes look like.
Training neural network
Since my tick list only contains 55 routes, I will train a supervised neural network on the full 116.000 routes using the average ratings of the community. Secondly I will apply transfer learning on my personal ticks to recommend new climbs.
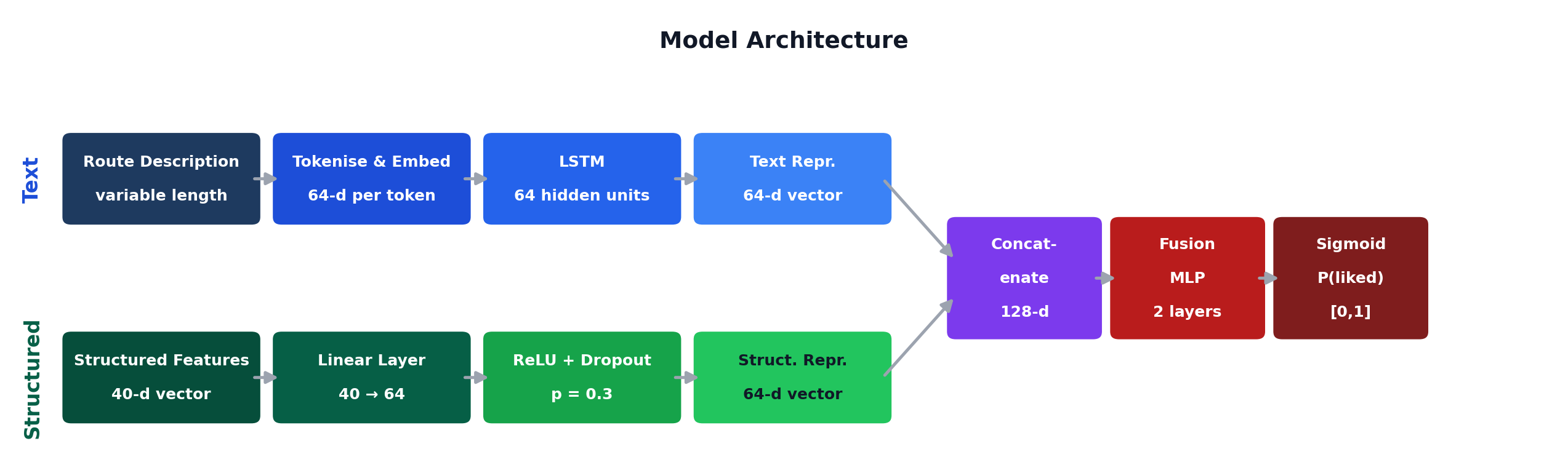
The model is a neural network trained to perform supervised binary (liked/not-liked routes) classification. It processes two parallel inputs; the route description as text and structured features (e.g., grade, average star ratings), which are independently encoded with their own layers before being fused into a single prediction.
The route descriptions are tokenised and embedded into a 64-dimensional word vector space. Using LSTM (Long Short-Term Memory Network), the word vectors are then read in ordered sequence. In this way, descriptions like “not pumpy” are combined into a new vector, instead of two separate vectors “not” and “pumpy” that have very distinct meaning. The output is a single 64-dimensional vector, which is a compressed representation of the full description that retains the patterns most relevant for predicting route quality.
The structure feature vector consists of normalised climbing grade, average stars, 30 style keyword flags found in Blog 1, and 8 route type flags (e.g., sport, trad). They are passed through a linear layer, followed by a ReLU activation and dropout to prevent overfitting.
The two inputs are concatenated into a single 128-dimensional vector and passed through a fusion MLP (Multi-Layer Perceptron) that outputs a single value. This is converted to a probability between 0 and 1 via a sigmoid function, representing the likelihood that a route is liked.
Transfer learning on personal ticks
With the pre-trained weights from the community average ratings, we can use the network as a starting point for the personal recommendation. The model at previous stage encodes information on general climbing quality, and are now being fine-tuned exclusively on the 55 personal ticks, known as transfer learning.
I only have 55 learnable routes ticked: 80% (44 routes) are used for training and 20% (11 routes) for validation. The dataset is too small and therefore overfitting is an issue. This is why the model is built in two stages, where stage 1 is trained on community ratings, and while I accumulate more ticks, Stage 2 will increasingly personalize the recommendations and differ from the general opinion.
In the meantime, I apply two techniques to reduce overfitting, though more ticks are essential to make a truly personalized recommender work.
Since my ratings skew high, I would mostly have liked routes to learn from. Therefore, I apply a personalised threshold instead of the fixed 3.5 used for the community average. The threshold is chosen to maximize the F1 score on the validation set: $F_1=2(\text{Precision}\times \text{Recall})/(\text{Precision} + \text{Recall})$, where Precision is the fraction of recommended routes that I actually like, and Recall is the fraction of routes I would like that the model actually found. Maximizes the F1 balances avoiding recommending too many routes I dislike (low precision) while not missing the really good ones (low recall).
Each training epoch passes through the 44 training routes, after which the model is tested on the 11 validation routes it has never seen before. If the model is genuinly learning my preferences, the performances on both sets should improve. However, if it starts memorizing the training routes instead of learning patterns, the training performance keeps improving while validation performance plateaus or drops. This can be detected by early stopping. Performance is measured using the AUC (Area Under the ROC Curve), which captures how well the model ranks routes: the probability that it scores a route I liked higher than one I disliked, where 0.5 is random and 1.0 is perfect. If validation AUC fails to improve for 7 consecutive epochs, training halts and the best checkpoint is restored.
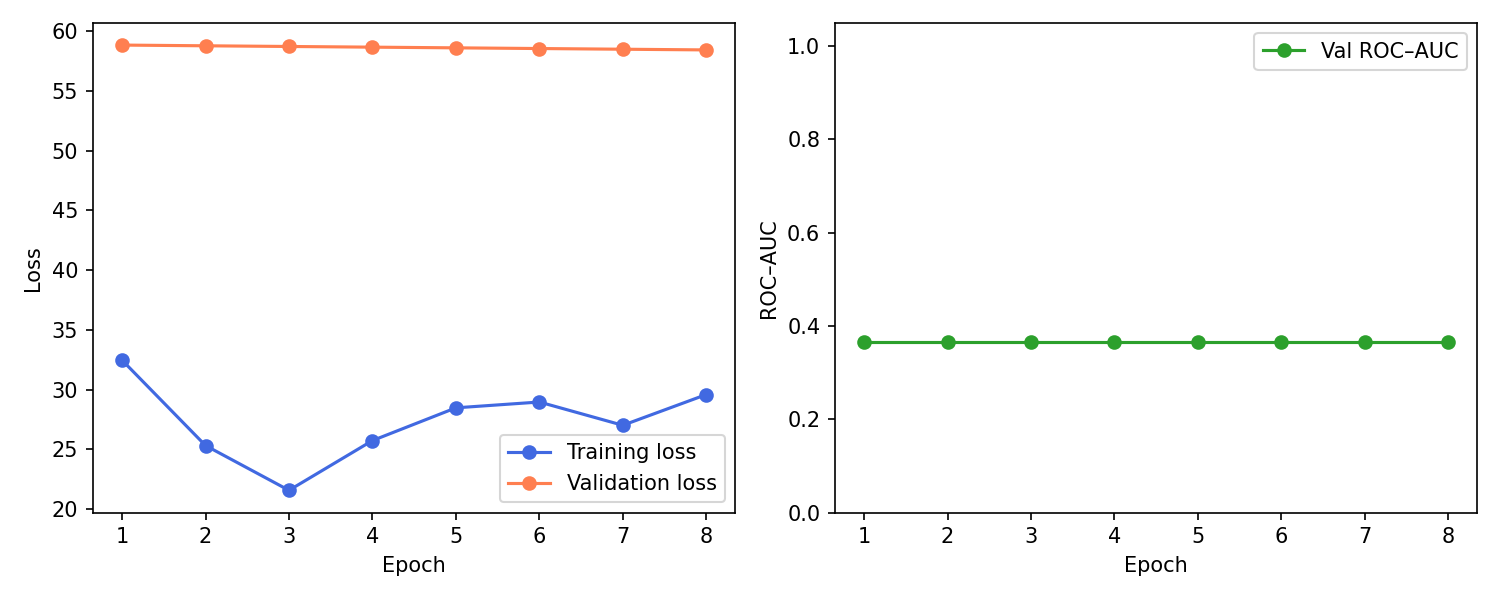
The training curves below show the limitation of fine-tuning on only 44 routes. The training loss drops first and then starts rising again slightly, which means the fusion head fits to tiny training set, and then begins to overfit its noise. Meanwhile the validation loss is almost flat and the model never really improves. The ROC-AUC $\approx 0.37$ is perfectly flat across epochs. On only 11 calidation route, the ranking is consistently worse than random (0.5) and does not change as training progresses. As a result, the recommendations are still useful, but they will reflect general climbing quality learned from community ratings rather than my personal preferences. This happens because I restore the checkpoints with the best AUC validation, and the globally pretrained model from Stage 1 achieves a higher AUC than anything the noisy Stage 2 fine‑tuning can reach until I add significantly more ticks.
Model evaluation
Does the neural network actually outperform simpler alternatives?
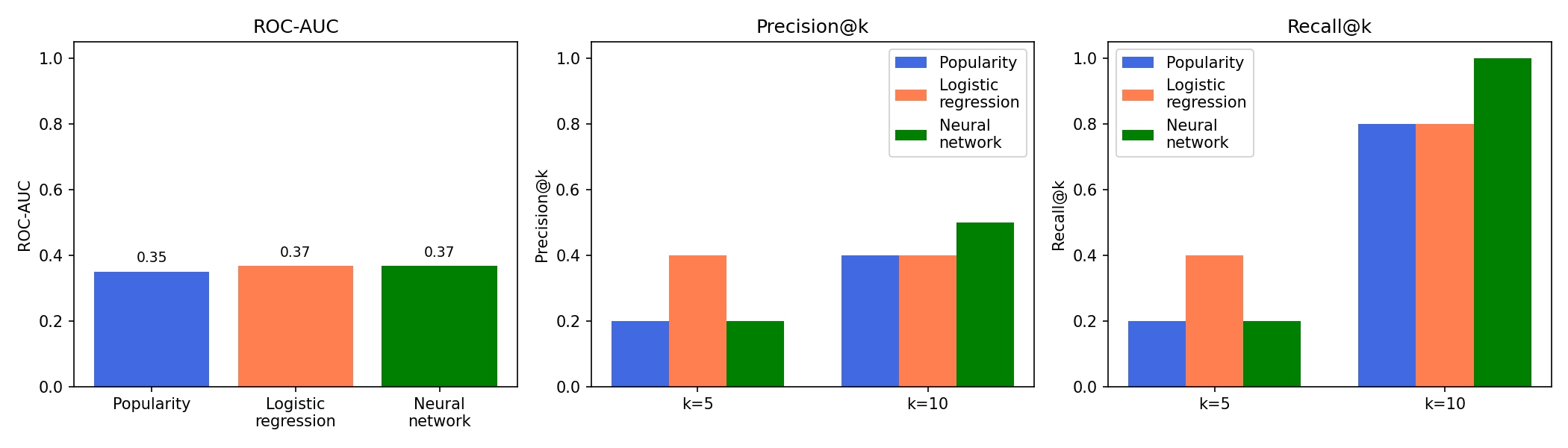
To answer this, I compare it against two baselines: a popularity model that ranks routes purely by community average stars, and a logistic regression trained only on structured features (grade, stars, route type etc.), excluding route description text. For all three models I evaluate the same validation routes using ROC-AUC and precision/recall at the top 5 and 10 ranked climbs.
Using only my tiny validation set of 11 routes, all three models have similar low ROC-AUC. However, the logistic regression performs best at k=5, while the neural network is better at k=10. This suggests that a simple structured model is competitive at the top of the list, while the neural network has more advantage a bit deeper into the ranking. As I add more ticked climbs in future, I expect the neural network to push further ahead of the simpler baselines.
Personal recommendations
See below tables of my top route and area recommendations including their score for ranking. Next trip to Oregon?!
| Rank | Area | Routes | Liked | Area score | Top route | Top route grade | Top route prob |
|---|---|---|---|---|---|---|---|
| 1 | The Main Wall > Trout Creek > Central Oregon > Oregon | 57 | 35 | 21.4912 | Gold Rush | 5.10- | 0.851816 |
| 2 | Flying Coconut Crags (Ciales) > Puerto Rico > North America > International | 29 | 23 | 18.2414 | Cabs Are Here | 5.10- | 0.666283 |
| 3 | Climbodia > Cambodia > Asia > International | 15 | 13 | 11.2667 | Snakeskin | 5.11d | 0.546383 |
| 4 | Chorreras > Paredes del Pantano > Chulilla > Valencia > Spain > Europe > International | 11 | 11 | 11 | Pim Pam Pons | 5.12a | 0.681215 |
| 5 | Little Russia > Nordegg > Alberta > Canada > North America > International | 16 | 13 | 10.5625 | Jenna`s bag of tricks | 5.10d | 0.630212 |
| Rank | Route | Grade | Area | Predicted like prob |
|---|---|---|---|---|
| 1 | A Brief History of Climb | 5.10b | The Gallery > Pendergrass-Murray Recreational Preserve (PMRP) > Red River Gorge > Kentucky | 0.950256 |
| 2 | Illusion Dweller | 5.10b | The Sentinel - West Face > The Sentinel > Real Hidden Valley > Joshua Tree National Park > California | 0.948802 |
| 3 | Serenity Crack | 5.10d PG13 | Western Royal Arches > Royal Arches > Royal Arches Area > Valley North Side > Yosemite Valley > Yosemite National Park > California | 0.946133 |
| 4 | Blue Sun | 5.10- | Way Rambo > Indian Creek > Moab Area > Utah | 0.940594 |
| 5 | East Buttress | 5.10c A0 | Middle Cathedral Rock > Cathedral Spires Area > Valley South Side > Yosemite Valley > Yosemite National Park > California | 0.936708 |